When I attended NAACL, I wanted to do a little test. I had two pitches for my LLM.int8() paper. One pitch is about how I use advanced quantization methods to achieve no performance degradation transformer inference at scale that makes large models more accessible. The other pitch talks about emergent outliers in transformers and how they radically change what transformers learn and how they function.
From that, I learned that quantization research is like printers. Nobody cares about printers. Nobody likes printers. But everybody is happy if printers do their job.
How that job is done for you through the bitsandbytes library with Hugging Face integration so that you can easily run OPT-175B and BLOOM-176B on a single machine is described in another blog post by my colleague and collaborator Younes Belkada.
This blog post will spill some mandatory details about quantization, but I want to mostly make it about these emergent features that I found in transformers at scale. I know the claims in the paper are highly robust. This blog post is a more speculative version of the paper that teases out the super curious details about the fascinating properties surrounding the emergent outlier features I found. I cannot spill all the details because my next project will delve deep into understanding these outlier features, but the space is so rich that I am happy to give you many curious details.
Mandatory quantization details
In a previous version of this blog post, I jokingly had a section with the big title “All You Ever Wanted to Know about Quantization” The section read: “If you quantize from 16-bit to 8-bit, you lose precision which might degrade model prediction quality.”
That is it.
Most people do not want to learn more about quantization — and honestly, the small sentence above is already enough information. The details are very gritty and complicated, but it is all in the code. The math and concepts are very simple and straightforward — if you have worked on quantization before. If you have not encountered quantization, it is likely a hot devilish nightmare that will eat your liver.
For those that say, “Pfff! Why do I need a liver anyways?”. Well, here you go. For others, just move ahead and read about the mysteries of emergent features.
What is quantization?
Let us say you have a data type I5 with values [0, 1, 2, 3, 4, 5] and a data type, I3, with values [0, 2, 4], how do you quantize from data type I5 to I3? You follow a two-step procedure:
- Normalize the range of I5 into I3.
- Round to the nearest value of I3.
Let’s do an example. Let’s say we have the vector [3, 1, 2, 3] in I5, and we want to quantize to I3.
Here the step-by-step recipe for quantization:
- We find the absolute maximum value of the vector: [3, 1, 2, 3] -> 3
- Then we divide by that value: [3, 1, 2, 3] -> [1, 0.33, 0.66, 1.0]
- And now we multiple by the range of the target data type I3, which is 4: [1, 0.33, 0.66, 1.0] -> [4.0, 1.33, 2.66, 4.0]
- Now we round to the nearest value: [4.0, 1.33, 2.66, 4.0] -> [4, 0, 2, 4]
We now converted [3, 1, 2, 4] in I5 to [4, 0, 2, 4] in I3. To dequantize, we reverse this process.
- Divide by 4: [4, 0, 2, 4] -> [1.0, 0.0, 0.5, 1.0]
- Multiply by the absolute maximum: [1.0, 0.0, 0.5, 1.0] -> [3.0, 0.0, 1.5, 3.0]
- Now we round again: [3.0, 0.0, 1.5, 3.0] -> [3, 0, 2, 3]
We see that our dequantization and quantization led to one error:
[3, 1, 2, 3] to [3, 0, 2, 3]
The second element changed from 1 to 0. This is a quantization error that leads to the loss of information in terms of how precise the information is encoded. If we have such errors and propagate them through many layers of a neural network, they accumulate, and they may change the result of a prediction and degrade the prediction quality.
How to make quantization methods more precise
Quantization can be enhanced in two ways. Use a better data type, or use more normalization constants (absolute maximum).
Regarding data types, Int8 is a terrible data type for deep learning. That is why I developed new data types in my research. However, currently, GPUs do not support other than Int8 data types on the hardware level, and as such, we are out of luck and need to use Int8.
The only way to improve quantization is through more normalization constants. A normalization constant squishes the input distribution, for example, I5, into the target distribution, for example, I3. We can increase precision, by squishing each vector only as much as is needed. For example, if you have the two vectors:
[3, 1, 2, 3]
[0, 2, 2, 0]
Then you can squish the first by 4 and the second by 2. This will give you twice the precision to quantize the second vector because the inputs are now spread over a broader range of the I3 data type. In fact, the second vector can be quantized without errors if you use an additional absolute maximum value. If you use only a single constant over both vectors (tensor-wise constants), then you will have two errors.
Vector-wise quantization
So now that we know how to make quantization more precise, how do we achieve maximum precision for matrix multiplication?
The key is this: If we use different normalization constants for dependent vectors, we then need to recover this information in the dequantization step. For example, if we subtract a constant to center one distribution over another: (A-minA)(B-minB) then to dequantize the output in A*B=C we need to do:
A*B = C
(A-minA)(B-minB) = A*B – A*minB – B*minA + minA*minB = C – A*minB – B*minA + minA*minB
As such, dependent quantization produces additional computation, in this case, a couple of matrix-vector multiplications and additions which can be expensive (if we assume, A and B are matrices).
As such, we look for the most normalization constants we can get that are still independent. What does this look like?
We can see a matrix multiplication as a sequence of independent inner products between row vectors of A and column vectors of B. We can have a separate constant for each of these vectors. Denormalization happens by multiplying these two constants together for a particular element. No other computation is needed. This is vector-wise quantization. More details in the paper.
Mixed precision decomposition
Before we come to the emergent magnitude features, let me explain the last part of our method that is absolutely critical to achieving zero-degradation quantization at scales of up to 175B parameters.
So it turns out, that transformers have these emergent features that have very large values. They occur in particular hidden dimensions and are active in up to 75% of all sequence dimensions. They occur in all layers (well most layers, but we come to that). So if you have a transformer hidden state X of dimensionality [batch, sequence, hidden], then X[:, :, i] for some i have values that look like this:
[-60.. -45, -51, -35, -20, -67]
Whereas 99.9% of dimensions look like this (normally distributed with one outlier)
[-0.10, -0.23, 0.08, -0.38, -0.28, -0.29, -2.11, 0.34, -0.53, -67.0]
If we quantize and dequantize a row without an outlier, we get this:
[-0.10, -0.23, 0.08, -0.38, -0.28, -0.28, -2.11, 0.33, -0.53]
only a single error, -0.28 instead of -0.29, at the 0.01 precision level. However, if we quantize the same vector with the outlier, we get this:
[ -0.00, -0.00, 0.00, -0.53, -0.53, -0.53, -2.11, 0.53, -0.53, -67.00]
In other words, even if we use vector-wise quantization, we squish a lot of information to zero and have large errors. On average, vectors without outliers have a mean error of 0.015. This vector has an error of 0.12. Do this for a couple of layers, and we remove all information and end up with pure noise.
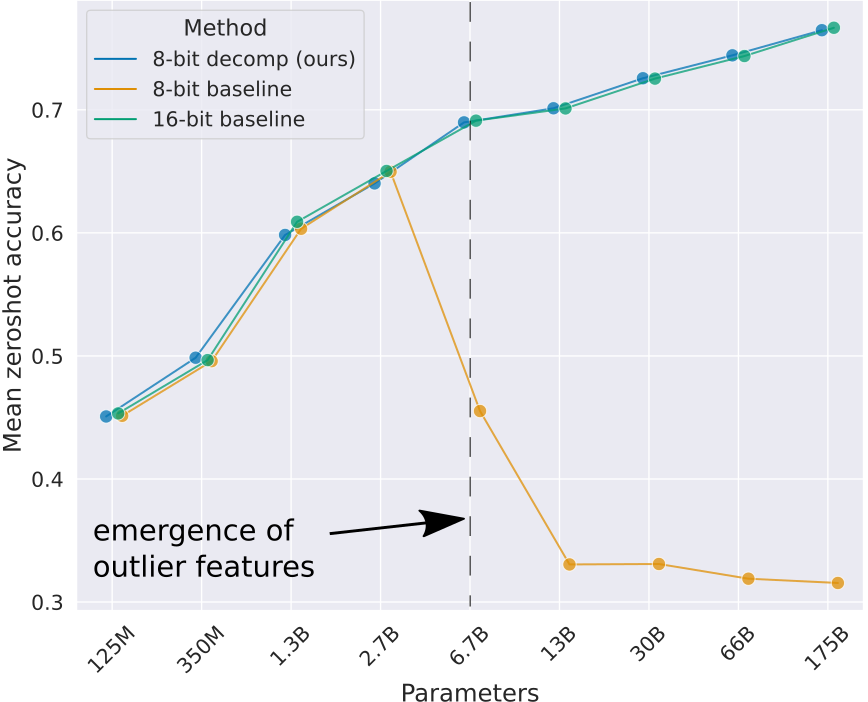
The problem is that at a scale of 6.7B parameters and above, 75% of hidden state sequences are affected. So this absolutely wrecks quantization.
The good news is that these outliers are highly systematic. While you have 150,000 outliers per sequence in a 6.7B transformer, they only occur in 6 feature dimensions (6 different indices “i” as in X[:, :, i]).
As such, we can separate these emergent features into a separate, high precision matrix multiplication, quantize the other 99.9% of values to Int8, can combine the output of both matrix multiplications. This avoids the information squishing to zero effect, and we can recover full transformer performance.

Results
The results show that this method works well. We can recover full performance by using the LLM.int8() quantization procedure. You can clearly see that there is a big dip in performance for the 8-bit baseline, which is vector-wise quantization. We need both vector-wise quantization and mixed precision decomposition, that is, the full LLM.int8() method to recover full performance. Either of these methods alone is not sufficient.
Emergent Features
There are a lot of exciting findings in the paper:
- Emergence is not sudden but gradual and grows according to an exponential function related to perplexity and not model size.
- Outlier features grow very quickly once their phase shift occurs.
- The number of outliers features is strictly proportional to perplexity.
Many other findings did not make it into the paper because these were too difficult to verify robustly, but I wanted to share them here anyway. Since these results are less robust, take them with a grain of salt.
But I am jumping ahead: What is the emergence, and what makes an emergent feature? If I put it in my own words, I would say:
Emergence is a gradual change in a property that suddenly undergoes a phase shift and then changes the quality of its substrate.
Let’s think step-by-step.
Substrate: Transformer
Property: Very large features in particular hidden dimensions across the transformer
Gradual change: Decreasing perplexity, more and larger outlier features
Phase shift: Outlier features suddenly become available in all transformer layers and coordinate through a few hidden dimensions.
Change of quality: Highly sparse, almost discrete attention; very dense FFN layers; “dual attention”; long-range attention (?); stable training through increased numerical stability.
Some additional terms. What is a feature?
If you have hidden state X that is passed along a transformer with dimensionality [batch, sequence, hidden], then a feature is a particular dimension X[:, :, i], which offers some weak explanation for the label.
Emergent Features in a Nutshell
To get a little sense of what this is all about, here is a short explanation encapsulating everything important about emergent features.
The most intuitive explanation of feature outliers is that transformers have two processing streams. One stream learns features that explain the inputs, and the other stream learns features that remove other features. Removing noisy, context-irrelevant features is the key to making accurate predictions. The more noisy, context-irrelevant features you remove in early layers, the less conflicting high-level features you have in later layers.
For example, if you classify dogs vs. cats, it makes sense to “sharpen” the key features that make these animals different (e.g. cat eyes, cat ears) and remove the similar features (fur color and potentially texture). This is particularly relevant if you have many noisy “weak” features as in natural language processing.
If you take this mechanism to an extreme, you can get discretization, which goes hand-in-hand with context-dependent memory and “reasoning” over elements. Discretization means, you have, say, 100 features, but you decide to remove 99% of them by setting them to zero, and you amplify the rest. The result is a single feature that is now a discrete entity. Once discretized, this entity can be stored and reused later.
To coordinate these streams throughout the transformer, it is useful to dedicate certain hidden dimensions to the functionality of removing other features. That way, if the transformer needs to remove features, it knows beforehand which feature dimension to access to perform that functionality.
How do you remove features? You have a single dimension with very large positive or negative values, and you multiply that dimension with a positive/negative number.
Take the following matrix, which is similar to how emergent features are represented in hidden states.
[0, 1, -60, 4]
[3, 0, -50, -2]
[-1, 0, -55, 1]
[3, 2, -60, 1]
If we want to remove, say, features (columns) 0 and 3 in a matrix multiplication followed by a non-linear function, all we have to do is to multiply everything by a negative number and multiply the outlier feature for columns 0 and 3 by a positive number. If we do this with negative and positive 1s, it looks like this:
[-1, -1, -1, -1]
[-1, -1, -1, -1]
[ 1, -1, -1, 1]
[-1, -1, -1, -1]
We receive the following after a softmax:
[0, 0.5, 0.5, 0]
[0, 0.5, 0.5, 0]
[0, 0.5, 0.5, 0]
[0, 0.5, 0.5, 0]
The neat thing about this system is, that if you always maintain the outlier feature in dimension 3, you know beforehand where to insert a positive number to remove a feature (row 3 of the other matrix).
Transformers seem to coordinate these dimensions throughout all layers except the attention function and the second feedforward network where these outliers are “consumed” to remove features.
This means that transformers always use a certain dimension for these outliers, and each layer “knows” beforehand how to remove a feature because these feature dimensions always have very large values with a particular sign (some are negative, some are positive).
However, this full “coordination” through a single dimension only happens after the phase shift. Before the phase shift, in transformers with less than 6.7B parameters some layers disagree which dimension to use for these large features.
How Emergent Features Emerge
Emergent outlier features are present in even very small transformers (125M parameters), and they do start out in the attention projection layers (key/query/value). Feature outliers are “consumed” in the attention function (softmax) and the second fully connected sublayer (contraction layer). The outlier features are likely consumed in these layers since the second feedforward network (FFN) sub-layer, and the softmax have non-linear functions that can easily squash features to zero.
Once you scale transformers a bit more (350M to 1.3B), outliers also occur in the FFN and attention output layers. At this scale, some successive attention layers and FFN layers use the same dimension to coordinate what features to remove. This has synergy. The attention layer is good at context-dependent selection and pattern matching, while the FFN layers are good at globally, context-independent pattern matching.
At this scale, however, outliers are still probabilistic. This means they occur mostly in some dimensions, but these dimensions can change slightly from mini-batch to mini-batch and between layer and layer. At this scale, layers have not yet learned to coordinate outlier features through the same dimension. This makes it more difficult to remove unwanted features.
At the 2.7B to 6B scale, things become much more coordinated. Now 60% of layers agree on which outlier dimension to use.
The phase shift happens around 6.7B, where 100% of layers use the same dimension for outliers. At this point, a couple of things happen rapidly:
- Outliers become very large quickly. They grow from about 15 for a 6B model to about 60 for a 13B model. OPT-66B has outliers of size around 95, which indicates this growth phase is temporary.
- Attention layers become very sparse. The attention is very concentrated so that just a few sequence dimensions determine the top probability and the overall probability mass. Almost all sequence dimensions have zero probability. However, this is still context-dependent, and the transformer seems to be “unsure” what to attend to for some sequences.
- FFN layers become more “dense”. While in computer vision, you can prune about 95% of weights without severe performance degradation, that number is 30% for transformers trained on NLP data. After emergence, this number shrinks to well below 5%. It seems that canceling out features can remove noise that is generated from the many weak features that are activated. Because these are silenced now, each set of neurons can learn much more features that are almost independent of each other due to the masking of context-dependent features.
- Transformers become more stable. If you treat the outlier features separately, I believe you can probably run and even train transformers in less than 8-bit precision without degradation in performance.
The Most Important Take-aways for Your Research
You may say, “This is all good and well, Tim, but what does this mean for me and my research?” Good question! I think it changes quite a bit.
There are two types of transformers and you should not generalize from one to the other.
From these findings it is clear that transformer after the phase shift at 6.7B parameters behave very different to transformers before the phase shift. As such, one should not try to generalize from <6.7B transformers to beyond 6.7B parameters.
But training and using 6.7B transformers can be pretty painful. At Facebook AI research, I had a 1.3B parameter baseline and I would usually run 2-3 of those models on 128 GPUs each for a total of 384 GPUs. Despite these massive resources it would still feel “slow” in that my research progress was mostly hindered by compute. I imagine to train 6.7B models on 8 GPUs or even 32 GPUs must be super painful. Is there a way that we can avoid this?
I think another key finding from the paper can help. We found that emergence of features occurs smoothly according to an exponential distribution of decreasing perplexity. As such, one could do the following.
We train multiple smaller models, say, 125M, 350M and 1.3B parameters, and then we measure the emergent property in those models and relate it to the property that we are interested in analyzing, for example, a new architecture or a new from of interpreting models. Once we gathered this data, we can measure how the change in the emergent property changes the results of our new method. With that, we might be able to determine if our new method generalizes to models beyond 6.7B parameters.
While, by definition, the phase shift leads to a stark change in behavior, this method of extrapolating emergent behavior might yield more robust predictions for your research. It would be effortful and complicated to do this, but this is better than “wishful thinking” research that does not generalize.
We might be able to find new emergent properties by studying “scaling laws of emergence”.
The finding that emergence can be measured in small models means that new emergent properties that require models larger than 175B parameters might be already measurable in the open-source OPT models.
If we can correlate statistics of a property with increasing capabilities and if this property follows a function that will eventually, “threshold”, we might have discovered a new emergent property that leads to new capabilities.
Conclusion
In this blog post, I introduced LLM.int8() and gave an introduction into the emergent features that we discovered in language model at scale. I discussed the implication of these emergent features in particular how it relates to generalization.
 to Get for Deep Learning: My Experience and Advice for Using GPUs in Deep Learning")

awfidius says
Couple of buglets in the (very nice) I5->I3 example.
Let’s do an example. Let’s say we have the vector [3, 1, 2, 3] in I5, and we want to quantize to I3.
Here the step-by-step recipe for quantization:
We find the absolute maximum value of the vector: [3, 1, 2, 3] -> 3
Then we divide by that value: [3, 1, 2, 3] -> [1, 0.33, 0.66, 1.0]
And now we multiple by the range of the target data type I3, which is 4: [1, 0.33, 0.66, 1.0] -> [4.0, 1.33, 2.66, 4.0]
Now we round to the nearest value: [4.0, 1.33, 2.66, 4.0] -> [4, 2**, 2, 4]
We now converted [3, 1, 2, 3**] in I5 to [4, 2**, 2, 4] in I3. To dequantize, we reverse this process.
Divide by 4: [4, 2*, 2, 4] -> [1.0, 0.5, 0.5, 1.0]
Multiply by the absolute maximum: [1.0, 0.5, 0.5, 1.0] -> [3.0, 1.5, 1.5, 3.0]
Now we round again: [3.0, 0.0, 1.5, 3.0] -> [3, 2, 2, 3]
We see that our dequantization and quantization led to *an* error:
[3, 1, 2, 3] to [3, 2, 2, 3]
The second element changed from 1 to 2. This is a quantization error that leads to the loss of information in terms of how precise the information is encoded. If we have such errors and propagate them through many layers of a neural network, they accumulate, and they may change the result of a prediction and degrade the prediction quality.
Tim Dettmers says
Thanks for pointing out the error!
Vivek Kumar says
Thanks for such a detailed blog post. Very helpful!
I have a question in the section “How Emergent Features Emerge”, #2 topic, “Attention layers become very sparse”. Is this sparsity > 20%? Could we just use pruning during training to handle the sparsity well? To improve performance during inference, is it good to just use H/W supported sparsity (block or scattered) ?
Any comment in this regard to improve performance during inference would be helpful.
Thank you.
Tim Dettmers says
The sparsity is in the multiplication of the hidden state, so we can only prune dynamically with each example. Theoretically, that is possible, but its difficult to do this efficiently since it is a scattered pattern that is not well accelerated on hardware. However, the sparsity can be very high (99%) but some samples are relatively dense (40% sparsity).
Vivek Kumar says
Thank you Tim!
We are looking at scattered sparsity to boost inference performance. And, it does come with an additional penalty and anything above 20% sparsity is a bonus.
Samuel says
Error in the first quantization example.
The vector originally posited (first example) was: [3,1,2,3], not: [3,1,2,4]. This leads the author to erroneously cite 2 errors when there is only 1.
Tim Dettmers says
Thanks for pointing this out!
sva says
I believe you have a small error. In the beginning you say,
> Let’s do an example. Let’s say we have the vector [3, 1, 2, 3] in I5, and we want to quantize to I3.
But then you say,
> We now converted [3, 1, 2, 4] in I5 to [4, 0, 2, 4] in I3. To dequantize, we reverse this process.
Great article nonetheless. I learned a few things today!
Tim Dettmers says
Thank you for noticing — fixed!
Ben Harper says
Thanks, this is so clear and easy to follow! I really appreciate blog posts like this.. and great work.
Tim Dettmers says
Thank you 🙂
Jonathan Kummerfeld says
This is very cool work! Do you think this mechanism of coordinated dimensions for removing features could be achieved with a modification to the transformer architecture instead? In other words, modifying the transformer structure itself to get the benefits that currently only 6.7B+ parameter models can learn?
Tim Dettmers says
Yes, it seems that is possible. In a current collaboration we alter the transformer architecture and see faster training. However, we have not analyzed the dynamics of the outliers.