This is my data science portfolio where I present some results from some hacks from hackathons and unpublished results from my previous research.
Image Search for Fashion via Deep Autoencoder
Abstract
Here I scraped and preprocessed 420000 fashion images from several websites and trained RBMs which I unrolled into a deep autoencoder to find clothes which are similar to clothes in a given image. The results were reasonably good for images of clothes, but poor for cropped images of clothes worn by people.
Methods
Images where scraped from several fashion websites and were preprocessed with a Sobel filter to learn the shape of the clothes instead of their color. Weights were pre-trained by stacking restricted Boltzmann machines (RBMs) which were unrolled into an autoencoder with a code layer of size 256 (architecture: 21000x2048x256x2048x21000). Similar images were then found by comparing the cosine similarity for all images. I used custom RBM and autoencoder implementations in python using gnumpy for GPU support.
Results and discussion

As seen in Figure 1 the autoencoder was sensitive to patterns (first image) and common details (clothes hangers in fourth image). The results were reasonably relevant with about 6-8 images of the same cloth category. The autoencoder codes did not incorporate fine details like the waistband on the mid-left dress in the third image. When used on cropped images of clothes worn by people, the results were poor (fifth image), as pose and orientation strongly influenced the results. More images or better preprocessing techniques would be needed to get reasonable results for such cropped images.
Using Neural Word Embeddings for Food Pairing Suggestions
Abstract
A web-app was designed where users should receive suitable suggestions for adding a food ingredient to a number of already selected food ingredients. To generate these suggestions, I learned neural word embeddings (word2vec) on recipe data. The suggested ingredients fitted well with the already selected ingredients. However the suggestions via the word embeddings got quickly stuck in a particular cuisine, e.g. Mediterranean cuisine, and rare but working food pairings were never suggested.
Methods
An open data recipe database of 50000 recipes was preprocessed so that it could be used with the word2vec tool to generate neural word embeddings. In the case of recipe data, which features much less smaller vocabulary with repetitive words, it was imperative to use a very small word window surrounding the central word (window size = 1) and penalize common words heavily, e.g. omit cases of tomato with high probability.
Results and discussion

Using neural word embeddings created many distinct clusters for each regional cuisine as shown in Figure 2. This worked surprisingly well for this task even when the amount of the data was limited (about 250000 words). The resulting recommendations where quite good, so that a fitting ingredient could be found from two or more existing ingredients. However, when two or more ingredients were picked, most suggestions were only from the same cluster of regional cuisine and unusual pairings that work, like pineapple on pizza, were not suggested.


Figure 4: t-SNE plot of word embeddings conditioned on Mexican cuisine. One can see that tomato moves out of the Mediterranean cluster and is now closer to food ingredients more distinct to the Mexican cuisine, e.g. bell pepper and kidney beans.
From Figure 3 and 4 one can see, that conditioning on one ingredient or cuisine changes the constellation of the clusters in a reasonable way. When conditioned on the Mexican cuisine, some ingredients which are typical of both Mexican and other cuisines, e.g. tomatoes, move closer to the new Mexican cluster to reflect typical Mexican food pairings. However, in the case of tomato, the distance to the Mexican and Mediterranean cuisine is still about equal even after conditioning for Mexican cuisine. This shows that the neural network learned that tomatoes are prototypical for the Mediterranean cuisine.
Finding Influencers on Twitter with Weighted PageRank
Abstract
The task was to find potential new bloggers for a news agency which are socially connected to existing bloggers on the news website. The Twitter social network of the existing bloggers was scraped and a weighted PageRank was calculated. With a analysis of conversations between existing bloggers and other twitter users, potentially influential new bloggers could be identified.
Introduction
New bloggers should be found for a news agency who are influential in their field of work. Success of convincing these potential new bloggers to blog for the news agency was thought to be increased significantly if there was a social relationship with an existing blogger: “Hey, your friend is blogger for our news website, would you like to blog for us, too?”.
Methods
The Twitter handles of the existing bloggers were scraped and 80 friends and followers were obtained via the Twitter API. Then 20 friends and followers of the friends and follows was obtained to build a social network. Due to the twitter rate limits. The total count of followers and friends for every twitter user was also obtained. A weighted PageRank was calculated with a weight of 1 for the scraped social network and each twitter user also received two additional nodes, with a single connection to that user with the weight equal being to the number of total followers and friends.
Results

Screenshot of a table on the finished web-application. On can see that the influence in the network is marked by preferences of the initial bloggers as German twitter user often have larger PageRank than comparable US users.
Improving Deep Learning Performance with Dropout Decay
Abstract
I took part in the Crowdflower Kaggle competition in which it was the task to predict weather labels (e.g. sunny, cloudy, cold, hot) from twitter data. I used a deep neural network with rectified linear units and placed 2nd. The data was preprocessed with regularized tf-idf. Dropout decay was used which greatly increased the performance of the model. The resulting model was superior to ensembles of linear and tree-based models and was comparable in performance to models that used additional feature engineering and specialized twitter tokenizers.
Introduction
The task was it to predict how likely 24 different weather labels were for a given tweet, e.g. “Let’s hope all this nice weather doesn’t mean a rainy cold summer!”. The training data labels are grouped into three categories: Sentiment (e.g. negative, neutral), time of weather (e.g. future, past), type of weather (e.g. hot, snow).
Methods
The data was preprocessed with tf-idf and the vocabulary was capped at 200000 words; stopwords were omitted. After using a single linear and three separate logistic regressions I found that linear regression was better and I optimized the parameters for that model. After that I limited the vocabulary to 9000 words and trained a deep neural network (DNN) with rectified linear units and 9000x2000x2000x24 architecture on the tf-idf data. Outputs were truncated to be in the ![[0,1]](https://s0.wp.com/latex.php?latex=%5B0%2C1%5D&bg=ffffff&fg=000&s=0&c=20201002)
Results

The DNN was weighted nine times stronger in the ensemble than the ridged regression (RR). This suggests that the DNN performed significantly better than a single RR. A ensemble of a DNN and RR performed equally well as multiple RRs with which model stacking was performed, i.e. the RRs feed into another RR together with the original tf-idf inputs.
However, a DNN with dropout decay outperformed the model stacking approach and was only bested by model stacking combined with additional feature engineering and a specialized twitter tokenizer (see Table 1). Thus dropout decay significantly increased performance. Rapid overfitting was observed when the learning rate was held steady after halving dropout, and similarly, no gains in performance occurred when the momentum was maintained after halving dropout. It was also observed, that dropout decay improved performance the most when the input dropout rate was high 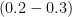
Discussion
The results show that a deep neural network performs as well as simple algorithms which were trained on an elaborate set of hand-engineered features which included features from sentiment analysis, part of speech tagging and tf-idf features from a specialized twitter tokenizer.
Impressive was the decrease in root mean square test error after dropout decay was applied. However, poor results were obtained when learning rate was kept steady. A possible hypothesis for this behavior is, that the new information introduced into the network reveals a more accurate location of the local minima, which would otherwise be hidden in the induced variance of dropout. Because it is not likely, that the local minima of the training set is very close to a local minima of the cross validation set this also explains why a steady learning rate lead to rapid overfitting. Maintaining momentum probably lead to poor results because the momentum vector is composed of more noisy gradients which are adapted too slowly to the introduction of more precise location of local minima.
All in all, this work demonstrates that feature learning methods are on par with state of the art feature engineering. Large gains were observed after using dropout decay and this effect should be investigated in different circumstances to evaluate its significance.
Improving Dense Neural Network Parallelism with RMSProp
Abstract
Parallelizing dense architectures is an inherently difficult problem due to communication bottlenecks. Here I show that such bottlenecks can be widened by using RMSProp, a technique that adjusts the learning rate for each weight. I demonstrate this technique by using a GPU cluster to learn word embeddings with hidden layer on the English Wikipedia corpus and obtain improved speedups with respect to networks which do not use RMSProp.
Introduction
Efficient software exists (e.g. word2vec) that allows fast learning of word embeddings on large data sets, and these word embeddings do well on word similarity tasks. However, the word embeddings obtained in this way are shallow, i.e. no additional hidden layer is used in their computation. It was shown, that a learned hidden layer from a deep model could be used in many natural language tasks to achieve state-of-the-art performance. In this article, I developed a technique to speed up the learning of such deep models by using multiple GPUs. Here I show how RMSProp, a technique which modifies the learning rate for each weight, increases the speedup obtained from using multiple GPUs and also increases the learning relative to its computational costs. The current English Wikipedia dump was used to learn this model.
Methods
Preprocessing
The latest Wikipedia XML dump was firstly tokenized into sentences using the Python NLTK library. Then each sentence with less than 5 words was discarded. Punctuation of the remaining sentences was removed and each sentence was cut into windows of 11 words with respect to a middle word (5 words before and after each respective word in the sentence). For each word slot which stretched beyond the boundaries of the window the word “padding” was used as a filler word. The top 100000 most common non-stop words were determined and assigned an index. Then all windows of words were traversed and replaced with their respective index for each word; rare words were replaces with an extra “rare-word-index”.
Architecture
The architecture features a lookup table and a single hidden layer with ranking output function: The inputs were batches of word indexes which were fed into a lookup table layer that concatenated uniformly distributed initialized word vectors of size 64 to 256. This lookup table matrix was used as input to a hidden layer with non-linear activation function (sigmoid, or tanh). The next layer used linear output function with one-dimensional output and a ranking criterion. Each batch was fed twice through the network, once the original batch was used, the second time the same batch with middle word replaced by a random word was used. The following ranking criterion was then minimized which can be thought as increasing the geometric distance between the random word and other words in the window and decreasing it for all words within the original window:
![]()
where 

Implementation
Data parallelism was used to accelerate learning. This was done by splitting each batch into several sub-batches and then synchronizing gradients during the backpropagation pass. In the lookup table layer the gradients along their indexes for the words were used to synchronize the word embeddings. Nesterov’s accelerated gradient along with RMSProp was used. Nesterov’s accelerated gradient differs from classical momentum only in the timing of the update (1), which occurs before forward and backward propagation (2) and the weight updates (3):

where 







where 


RMSProp prevents that individual weights which have small gradients suffer from too small learning rates — with RMSProp the learning rate is normalized, so that good word embeddings are learned quickly even for rare words. Another advantage is, that rare but large errors are amplified and thus learned from more quickly. RMSProp can speed up learning by a factor of about three and makes learning more stable, in that certain weights do not get stuck during learning. Another advantage of using RMSProp is that it is computationally expensive which improves the ratio for communication/computation. Communication that synchronizes gradients among networks can thus be partially hidden under RMSProp calculation.
Hardware and software
Two nodes, i.e. computers, were used which were connected by a 40Gbit/s (5GB/s) Infiniband connection. The nodes had one and three GTX Titan GPUs, respectively. The minimal data transfer rate between GPUs within a node is 8GB/s. The Infiniband adapters where RDMA capable, which means that GPU buffers between nodes could be directly read and written from GPU to GPU not involving the CPU for conversion into a CPU buffer. This feature improved communication speed by roughly 15\% between nodes.
Results
Table 2 shows the speedups obtained during training with and without RMSProp. One can see that using RMSProp and hiding gradient communication under its calculation improves the speedup obtained when using multiple GPUs. One can also see, that the speedup is little or even decreased for architectures that feature larger hidden layers. This is due to the fact that the communication between GPUs is the bottleneck during training and that the rather fast Infiniband connection is still too slow so that networks need to wait for gradient synchronizations to be finished until each net can proceed to the next forward pass. This is a general problem encountered in data parallelism for neural networks.

Besides the increased speedup, RMSProp accelerated the learning significantly. While the computation of RMSProp increased the time needed to pass through the data set by about 50\%, the same cross validation score was reached about three times faster. This effect comes mainly that gradients for rare errors that are proportionally large are amplified. This effect might be less sophisticated for rectified linear or activation functions which have steeper gradients in general.

Discussion
Here I showed that hiding gradient synchronization partially under RMSProp calculation yields speedups when using multiple GPUs for training dense neural networks. While RMSProp increases the calculation time by about 50\% it enables three times faster learning which is mainly because the weights of rare words are learned more quickly. The increase in computation time improves the computation/communication ratio which in turn improves speedups in parallelization where communication is the bottleneck. On the other hand, It was also found, that this techniques does not scale to large architectures or to multiple nodes in the network. Model parallelism or asynchronous techniques need to be developed for such cases. However, the technique presented here might be viable to parallelize recurrent neural networks which are very difficult to parallelize due to their long sequential nature and often dense connectivity. Hessian-free optimization would be ideal to apply the same technique as used in this article, as Hessian-free optimization is computationally expensive yet very powerful for recurrent neural networks.