In my last blog post I explained what model and data parallelism is and analysed how to use data parallelism effectively in deep learning. In this blog post I will focus on model parallelism.
To recap, model parallelism is, when you split the model among GPUs and use the same data for each model; so each GPU works on a part of the model rather than a part of the data. In deep learning, one approach is to do this by splitting the weights, e.g. a 1000×1000 weight matrix would be split into a 1000×250 matrix if you use four GPUs.

One advantage of this approach is immediately apparent: If we split the weights among the GPUs we can have very large neural networks which weights would not fit into the memory of a single GPU. In part I mentioned this in an earlier blog post, where I also said that such large neural networks are largely unnecessary. However, for very big unsupervised learning tasks – which will become quite important in the near future – such large networks will be needed in order to learn fine grained features that could learn “intelligent” behavior.
How does a forward and backward pass work with such split matrices? This is most obvious when we do the matrix algebra step by step:
We start looking at 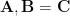
Standard: 128×1000 dot 1000×500 = 128×500
Split by weight matrix first dimension: 128×500 dot 500×500 = 128×500 -> add matrices
Split by weight matrix second dimension: 128×1000 dot 1000×250 = 128×250 -> stack matrices
To calculate the errors in the layer below we need to pass the current error through to the next layer, or more mathematically, we calculate the deltas by taking the dot product of the error of the previous layer 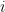
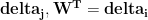
Standard: 128×500 dot 500×1000 = 128×1000
Split by weight matrix first dimension: 128×500 dot 500×500 = 128×500 -> stack matrices
Split by weight matrix second dimension: 128×250 dot 250×1000 = 128×1000 -> add matrices
We see here, we need to synchronize (adding or stacking weights) after each dot product and you may think that this is slow when compared to data parallelism, where we synchronize only once. But one can quickly see that this is not so for most cases if we do the math: In data parallelism a 1000×500 gradient needs to be transferred once for the 1000×500 layer – that’s 500000 elements; for model parallelism we just need to transfer a small matrix for each forward and backward pass with a total of 128000 or 160000 elements – that’s nearly 4 times less data! So the network card bandwidth is still the main bottleneck in the whole application, but much less so than in the data parallelism case.
This is of course all relative and depends on the network architecture. Data parallelism will be quite fast for small networks and very slow for large networks, the opposite is true for model parallelism. The more parameters we have, the more beneficial is model parallelism. Its true strength comes to play if you have neural networks where the weights do not fit into a single GPU memory. Here model parallelism might achieve that for which one would need thousands of CPUs.
However, if you run small networks where the GPUs are not saturated and have some free capacity (not all cores are running), then model parallelism will be slow. Unlike data parallelism, there are no tricks you can use to hide the communication needed for synchronization, this is because we have only partial information for the whole batch. With this partial information we cannot compute the activities in the next layer and thus have to wait for the completion of the synchronization to move forward.
How the advantages and disadvantages can be combined is best shown by Alex Krizhevsky who demonstrates the efficiency of using data parallelism in the convolutional layers and model parallelism in the dense layers of a convolutional neural network.

Vineet Gundecha says
Thank you for the informative post!
I would like to know where the parameter update happens for model and data parallelism.
In model parallelism, each GPU stores the gradients for the parameters that reside on that GPU. So, I guess the parameters are updated on the respective GPU accordingly. But for data parallelism, the gradients for each sub-batch are accumulated and the CPU performs the update?
Tim Dettmers says
For model parallelism, the updates happen on reach GPU respectively.
For data parallelism, the updates are accumulated for each GPU and each GPU updates its own parameters (with the same update as any other GPU). This is a bit faster than doing the updates on the CPU.
SK06 says
Hi Tim,
Can we do model splitting in image segmentation applications, i.e, for networks like fcn8s, fcn32s, fcn16s of https://github.com/shelhamer/fcn.berkeleyvision.org. Do caffe support model splitting. Which framework supports model splitting for image segmentation applications.
Thanks
SK
Tim Dettmers says
I assume with model splitting you mean splitting the model among multiple GPUs. This is also called model paralellism.
PyTorch supports this quite well: https://discuss.pytorch.org/t/model-parallelism-in-pytorch-for-large-r-than-1-gpu-models/778
It does not seem that Caffe supports model parallelism yet: https://github.com/BVLC/caffe/issues/876
Saqib Qamar says
Hello Tim,
Let me ask about Model parallelism in MPI-caffe. Is it supportable ???
Tim Dettmers says
Hello Saqib,
Caffe already uses C++ so integrating it with MPI should be straightforward. I believe there should be already be some wrapper for that already, but I do not know in how far caffe supports MPI out-of-the-box. But if you are interested in parallelism this would be an excellent point to start.
Krishna says
Hi guys,
I’m a beginner in deep learning. I clearly understand the concepts of Model and data Parallelism. I also tried implementing data parallelism using towers in tensorflow and running each tower in one GPU. Now i’m confused on the implementation of the MOdel parallelism. I don’t know how to communicate data between two GPU’s. I have a 2 GPU system. Can anyone explain or give me a link of some small snippet of code that explains how model parallelism is implemented.
Thank you
Tim Dettmers says
Hi Krishna,
here some code of my GPU library which implements a general matrix multiplication for an arbitrary number of GPUs. This is done using model parallelism:
https://github.com/TimDettmers/clusterNet/blob/master/source/clusterNet.cpp#L512
click here says
This is the perfect web site for anybody who
wishes to find out about this topic. You understand so much its almost tough to argue with you (not that I actually would want to…HaHa).
You definitely put a fresh spin on a subject that has been discussed for many years.
Excellent stuff, just great!
Tim Dettmers says
Hehe, thank you 🙂
Koshy George says
Very nice blog, explaining model parallelism.
” for model parallelism we just need to transfer a small matrix for each forward and backward pass with a total of 128000 or 160000 elements – that’s nearly 4 times less data!”.
I did not quite understand this statement. Let us take the case of the 128 x 1000 dot 1000 x 500 matrix multiplication. Let me try to explain what I have understood. The 128 long data is replicated to to two nodes A and B. Node A does 128 x 500 dot 500 x 500. Node B does the remaining 128 x 500 dot 500 x 500. They synchronize and add the 500 long results to get the final 500 long result. The total possible inter-node communication here in the forward pass is just 128 long data + 500 long result. For the backward pass, to compute the delta vector of a previous layer , one has to take the delta vector of the next layer and propagate it through the weight matrix backward. Again the communication here between the two nodes is just the 500 long final delta vector. The rest of the gradient computation is contained within each node.
Regardless of what I have understood, it would be great if you can explain this from your perspective, when you get time.
-thanks
Tim Dettmers says
So the first matrix A (128×1000) contains the inputs, while the matrix B (1000×500) contains the parameters / represents the weights. What you want to do in model parallelism is to split your parameters among all nodes, so that you have two 1000×250 matrices B1 and B2. When you matrix multiply this with the input you will get two matrices C1 and C2 with dimensions 128×250. You stack these matrices to get the full output matrix of size 128×500.
In the backward pass you matrix multiply with the errors which has the same dimension as C, so you do C dot B^T or in model parallelism C1 dot B1^T + C2 dot B2^T. Is that clearer now?
Jinho Seol says
Thank you for the great article.
But, still I don’t get it.
“In data parallelism a 1000×500 gradient needs to be transferred once for the 1000×500 layer – that’s 500000 elements; for model parallelism we just need to transfer a small matrix for each forward and backward pass with a total of 128000 or 160000 elements”
In the backward pass, 500000 elements are transferred in data parallelism (which is the same size of weight matrix) , whereas 160000 elements are transferred in model parallelism (which is much smaller size of weight matrix).
What does the difference come from?
Tim Dettmers says
In model parallelism we synchronize the activation and not the weights. In the example outlines the activations are smaller than the weights, thus less elements are transferred. This would be the opposite for convolutional nets and thus model parallelism is quite bad for convnets while data parallelism is quite good.
redfish says
Hey, thanks for those replies but,
How to get the results like 128000/160000?
Take above as example:
Standard: 128×1000 dot 1000×500 = 128×500
Split by weight matrix second dimension: 128×1000 dot 1000×250 = 128×250 -> stack matrices
As you mention in above reply,
“…model parallelism is to split your parameters among all nodes, so that you have two 1000×250 matricies B1 and B2. When you matrix multiply this with the input you will get two matricies C1 and C2 with dimensions 128×500. You stack these matricies to get the full output matrix of size 128×1000.”
In my understand:
A(128×1000) dot W(1000×500) can be split as
A dot B1(1000×250) = C1(128×250)
A dot B2(1000×250) = C2(128×250)
and stack C1, C2 together get a result of C(128×500)
I’m not sure why C1/C2 are dim. 128×500 in your reply..
And if my understand was right, (or maybe you’re right)
Still don’t know how model prarallelism sync through activations? and the calculations of 128000/160000..
Thanks a lot for helping me understand this!!
Appreciate.
Tim Dettmers says
Thanks for spotting the mistake, indeed it is a 128×250 matrix for C1 and C2 and they are then stacked.
The parameters come from both the forward (activation) and backward pass (errors):
128×500 (forward split-stack) + 128×500 (backward split-add) = 64000 + 64000 = 128000
128×1000 (forward split-add) + 128×250 (backward split-stack) = 128000 + 32000 = 160000
Hope that helps!
Alok says
I think there is a little update for the matrix C1 and C2 should be of 128×250 since the matrix B (1000×500) is split to 2 matrices of 1000×250 and when these would be multiplied with 128×1000 , produces 2 matrices of 128×250 .
Tim Dettmers says
This is correct, thanks for spotting this!
redfish says
Hey Alok,
So did you figure out how does 128000/160000 come from?
I still have no idea, and this kind of model parallelism seems manually partition of the model..
Appreciated if you shared your insight, thanks
Tim Dettmers says
See my new reply. Does this help? Let me know if it is still unclear!
redfish says
I see, thanks for the detail-clear reply, thanks a lot~